
ChatGPTなど、AIがいつの間にか進化しており話題になっていますので、AIの進化について学んでいきたいと思います。
ChatGPTでチャットしていると、何の支障もないため、AIと簡単に会話できるのではないかと思いますが、テキストによる自然言語処理と、音声処理は難しさが全然違います。
音声AIの課題
課題としては、
1.テキスト処理と比べると、音声は「波」である。
2.音声には、「時間」の要素がある
3.「音声認識」と、「音声合成」両方に課題がある
ということかと思います。
音声認識の進化に関して
音声認識の進化の歴史は、次のようになっています。
1950年代〜1960年代:
アメリカのベル研究所が、数字の1から9の音声を認識できるAudreyと呼ばれる音声認識システムを開発しました。
1970年代~1980年代:
音声認識技術は、パターン認識や統計的モデリングの進歩により、精度が向上しました。隠れマルコフモデル(HMM)にて音素を学習することで、様々なな単語に対応できるようになりました。
1990年代~2000年代:
ニューラルネットワークを用いた音声認識が注目されました。ニューラルネットワークは、HMMよりも高い精度を持っています。2000年代には、音声認識技術がスマートフォンに搭載され、音声アシスタントが登場しました。
2010年代以降:
音声認識技術は、ディープラーニングによるアプローチが主流となり、より高い精度と高速な処理が可能になっています。
ポイントとしては、音を最小単位の「音素」に分解・学習し、ディープラーニングによって「単語」に対応しているところです。

音声合成に関して
テキストを人間の声に近い自然な音声を生成する技術を「音声合成」と言います。
音声合成技術は、事前に録音した音声データを単位ごとに分割し、必要な単位をつなぎ合わせて音声を生成する方式で始まり、
現在では、事前に録音した大量の音声データから特徴量(発話者や感情など)を抽出し、ディープラーニングで必要な特徴量を生成して音声を合成する方式になっています。

音声AIの進化
音声AIの進化は、
①音声を単語単位で分割する方式
②音声を最小単位や特徴量に分割し組み合わせる
③大量の音声をディープラーニングで組み合わせる
という進化となっています。
音を単語や特徴量し、AIを使って最適な組み合わせにすることで、音をテキストに変換したり、テキストを音に変換することができます。
感情の理解と表現が伸びしろ
ChatGPTを使ったときに、知識やテキストによるコミュニケーションに関しては、すでにAI(人工知能)が人類の知能を超えると感じた方が多いと思います。
しかし、音声技術に関してはまだまだ伸びしろがあると感じます。
SiriやAlexaなどもそこまで使いこなせていないですし、ChatGPTと 「Talk-to-ChatGPT」というGoogle Chromeのプラグインを使っても、リアルタイムでの会話となるとまだまだと感じます。

他にも、Textから音楽を作る 「Text to Music」も、まだまだ成長の余地があると感じます。

つまり、音声とAIに不足しているのは「感情」です。音声のAIには、話している人間の感情を理解したり、テキスト化した文字に感情を表現して音声にする技術がまだ足りていないため、会話する気持ちになれないのではないかと思います。ですので、音声とAIは、感情の理解と表現が伸びしろになります。これからも音声AIの進化を見ていきましょう!!
まとめ
音声AIの進化についてまとめました。
最初は、パターンマッチから入り、その後、音の波を「音素」に分解して、これと単語を組み合わせ
そのご、ディープラーニングの技術で人間が話している言葉に変換しています。
テキスト処理に比べると、「文字情報」→「単語」というほど正解はなく、
音声は波なので、強弱、速さ、長さなどの要素があるため、まだまだ技術革新が必要と思われます。
また、音声読み上げに関してもサンプル数をいくつもとる必要がありますが、
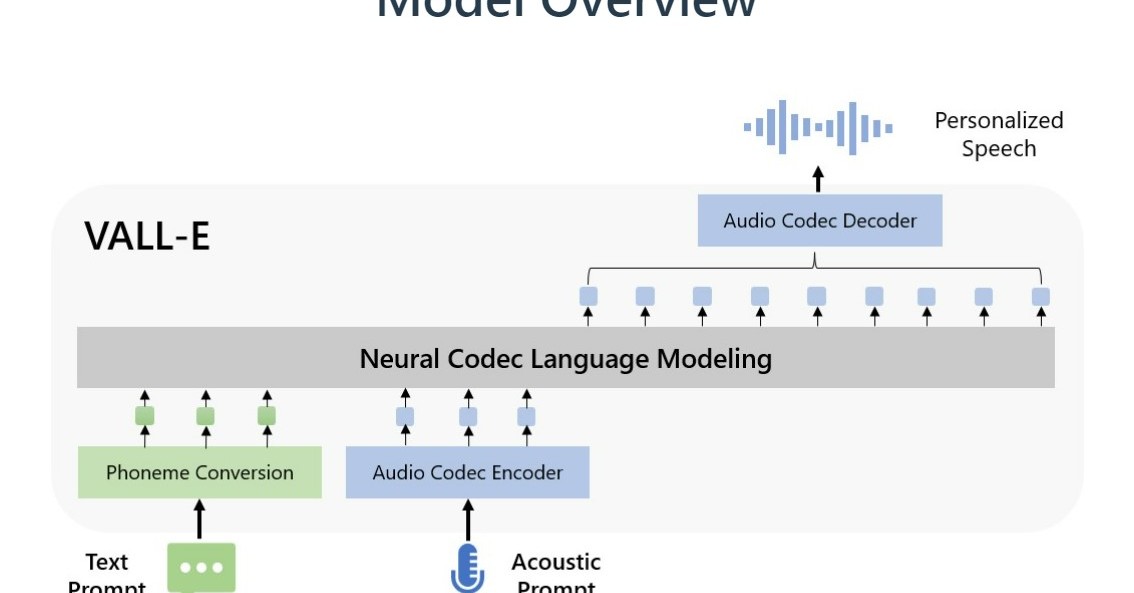
2023年1月にMicrosoftより、Microsoft、3秒分の音声だけでその人の声を真似るAI「VALL-E」のサンプルが公開されました。
これからは、少ない時間で自分の声を使ってさまざまな音声読み上げができるようになります。
現時点で、ナレーターのように音声を読み上げてくれる技術は確立しているので、あとは、「感情の理解と表現」がキーポイントだと思われます。
感情表現が豊かになると、AIの読み上げサービスも聞けるようになると思います。
これからも、音声AIの進化をウォッチしていきましょう!!
コメント