SadTalkerとは
SadTalkerとは、顔の画像とスピーチの音声から会話するムービーを作成する技術です。
人の顔の画像と音声ファイルを合成し、人が話しているような動画を作成してくれます。
以前、D-IDを紹介しましたが、似たような技術ですが、SadTalkerを使えばウォーターマークが無い状態で、人が話しているような動画が作成できますので紹介いたします。
D-IDに関しては、下記を参照して下さい。
SadTalkerの使い方
今回は、SadTalkerを直接起動し、Google Colaboratoryを使用しますので、特にStable Diffusion WebUIを起動したり、何かをインストールすることもなく、SadTalkerを実行する方法を紹介いたします。
Githubのページに移動してください
Google Colaboratoryサンプルがありますのでクリックして下さい。Colabと書いてあるものが、SadTalkerのサンプルになります。
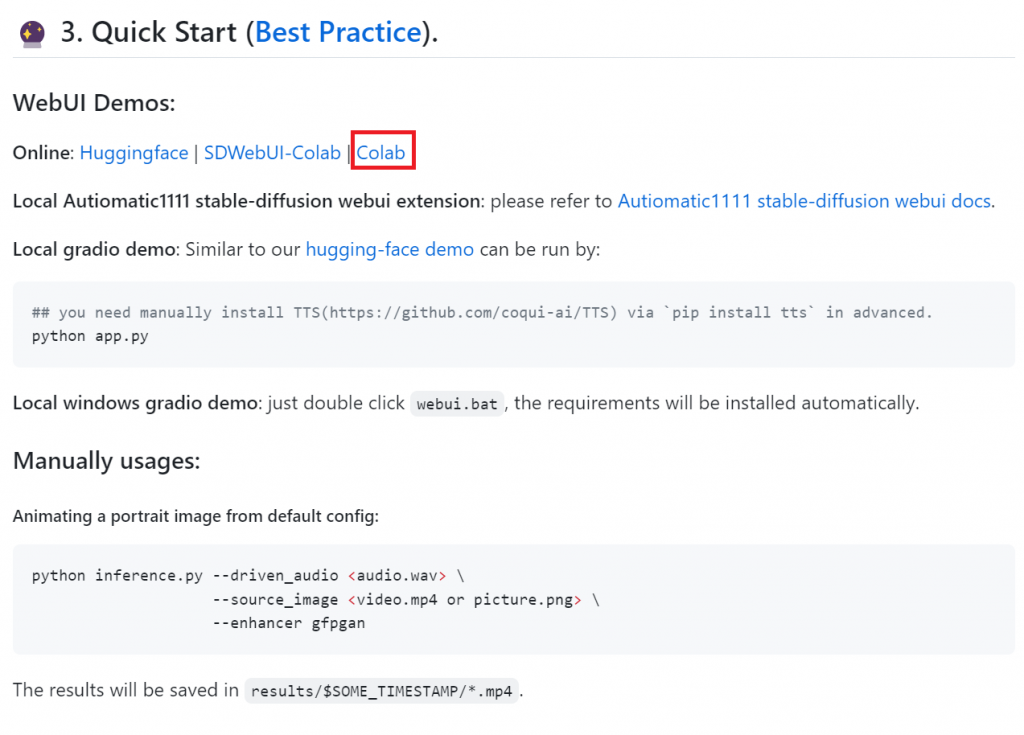
サンプル起動します。Google Colaboratoryが起動します。
Sad Talker 事前準備
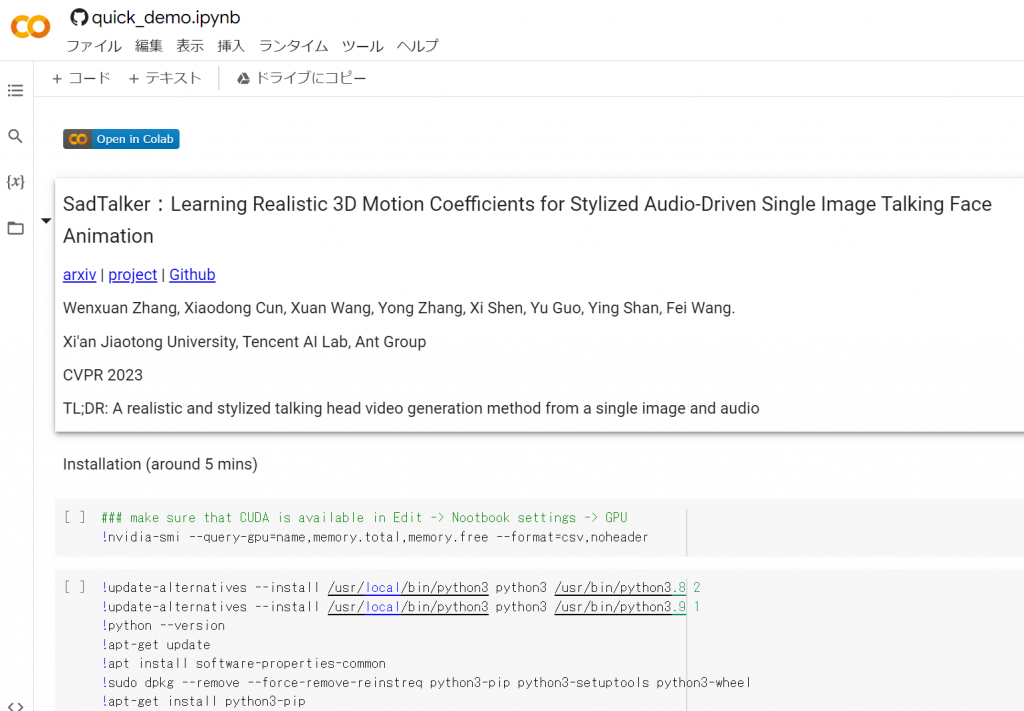
これからサンプルを実行していくのですが、
実行する際の事前の準備として、まずは、サンプルを自分のドライブにコピーしましょう。
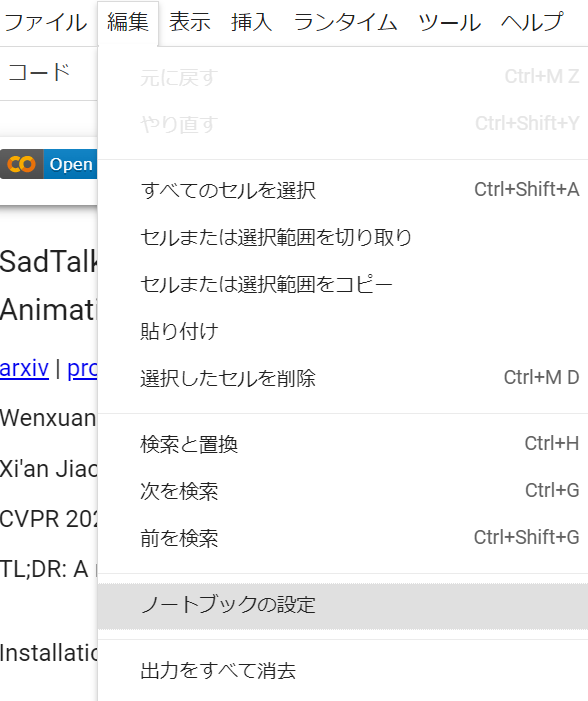
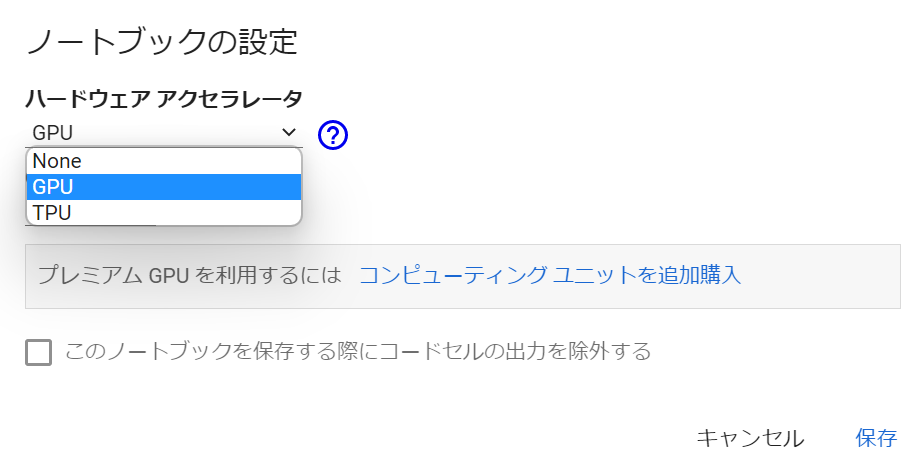
次に、Google Colaboratoryの「編集」→「ノートブックの設定」より、ハードウェアアクセラレータの設定を「GPU」を設定してください。
これで事前の準備はOKです。
SadTalker サンプルの実行
事前準備が完了したら、Google Colaboratoryで上から順番に実行していきましょう。
Installationから順番に行きます。around 5minsと書いてあるので、大体5分ぐらいかかります。気長に実行しましょう。
次は、Download modelsの実行です。約1分ほどかかります。
画像を選択する場面がありますが、気にせず実行していきます。

次は、Animationを実行します。
最後まで実行すると、可愛らしい女の子が英語で何かを話す動画が完成します。
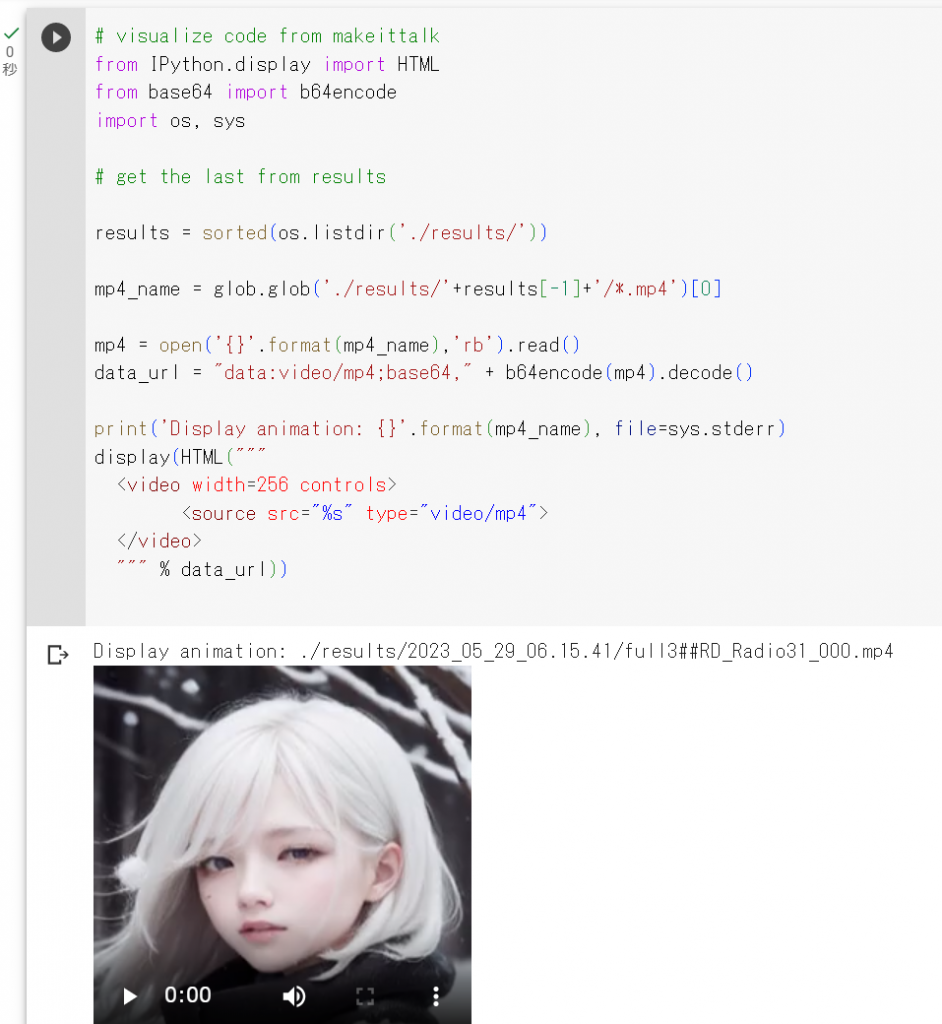
サンプルの実行は以上になります。
応用するためには、実行した環境をそのままにしておいてください。
SadTalkerの応用
一通り実行が完了したら、自作の画像ファイルを使って、好きな言葉を話してもらいます。
今回は、下記の勇者に話してもらおうと思います。

話してもらう内容は、Chat GPTにお願いすることにします。
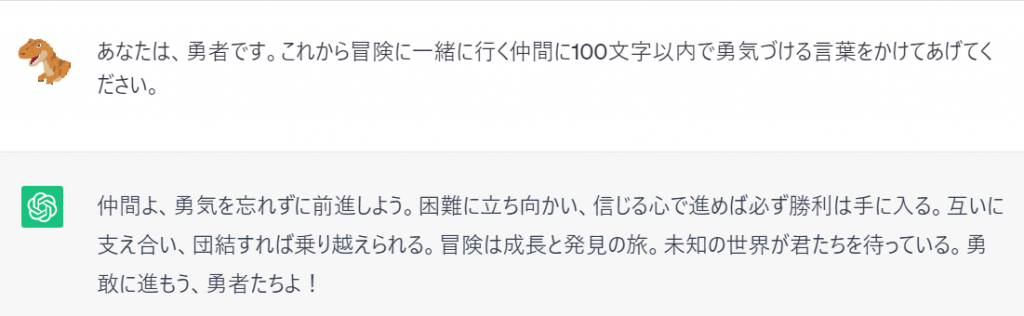
素晴らしい言葉をいただきましたので下記の言葉を音声に変換します。
仲間よ、勇気を忘れずに前進しよう。困難に立ち向かい、信じる心で進めば必ず勝利は手に入る。互いに支え合い、団結すれば乗り越えられる。冒険は成長と発見の旅。未知の世界が君たちを待っている。勇敢に進もう、勇者たちよ!
音声ファイルの作成
SadTalkerを使用するには、音声読み上げが完了したオーディオファイルが必要となります。
もちろん自分で読み上げた音声を webファイルやmp3ファイルにしても大丈夫です。
今回は、ChatGPTに作った文字を読んでもらうため、音読さんのホームページに行きましょう。

音読さんに先ほどのテキストを張り付けます。音声を選択して、「読み上げ」ボタンを押してください。
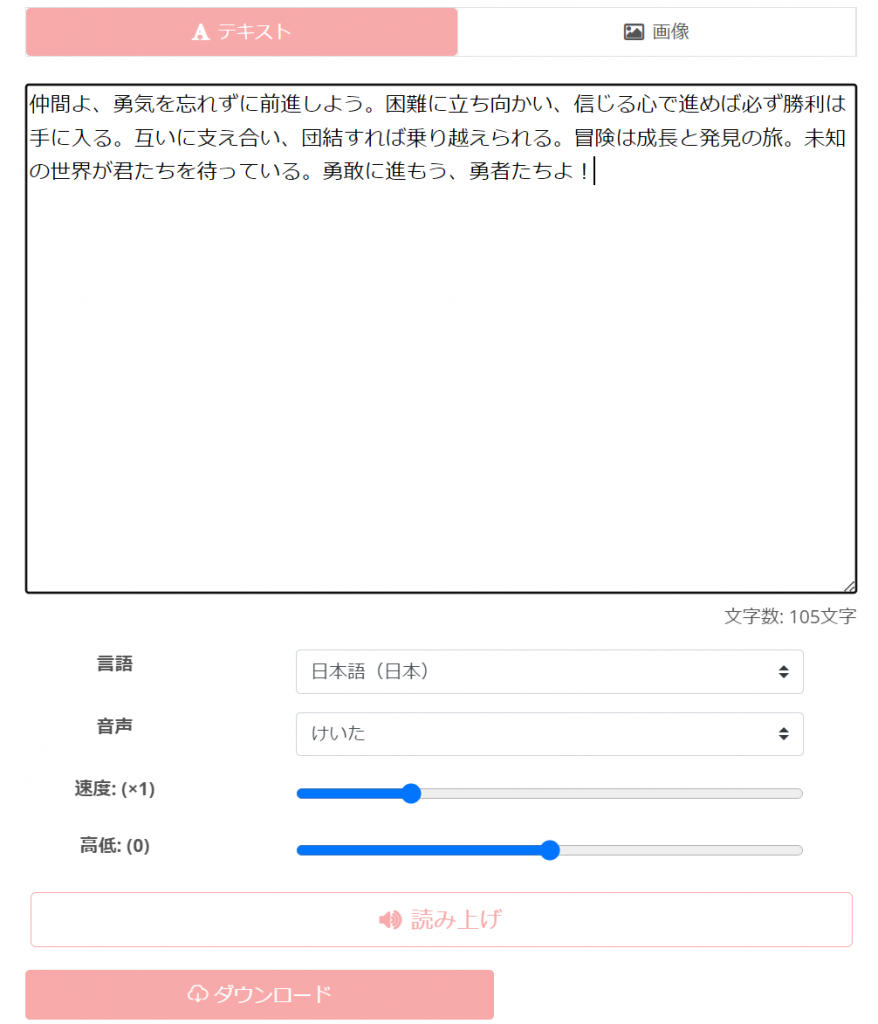
音声が完成したらダウンロードします。
画像ファイルと、音声ファイルが完成しました。
画像ファイルは、image.png、音声ファイルは、audio.mp3という名前にしておきます。
それでは、先ほどのSadTalkerのGoogle Colaboratoryに戻ってください。
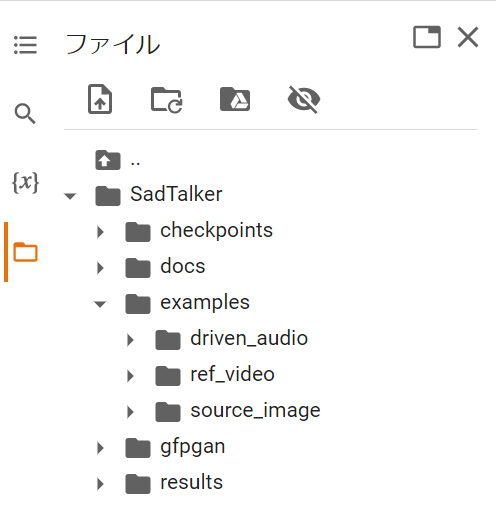
Google Colaboratoryの左側のフォルダアイコンをクリックすると下記のようにフォルダができますので、examplesフォルダの「source_image」にimage.png,「driven_audio」にaudio.mp3をアップロードしてください。
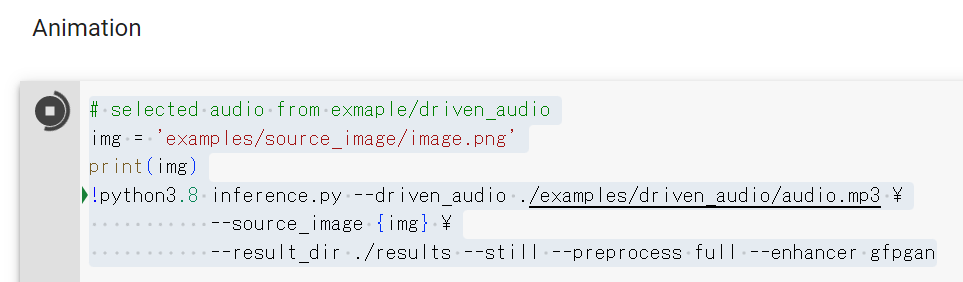
Animationのソースコードを修正します。
<修正前>

<修正後>

<修正後のソースコード>
# selected audio from exmaple/driven_audio
img = ‘examples/source_image/image.png’
print(img)
!python3.8 inference.py –driven_audio ./examples/driven_audio/audio.mp3 \
–source_image {img} \
–result_dir ./results –still –preprocess full –enhancer gfpgan
ソースコードを修正したらAnimationから実行してください。
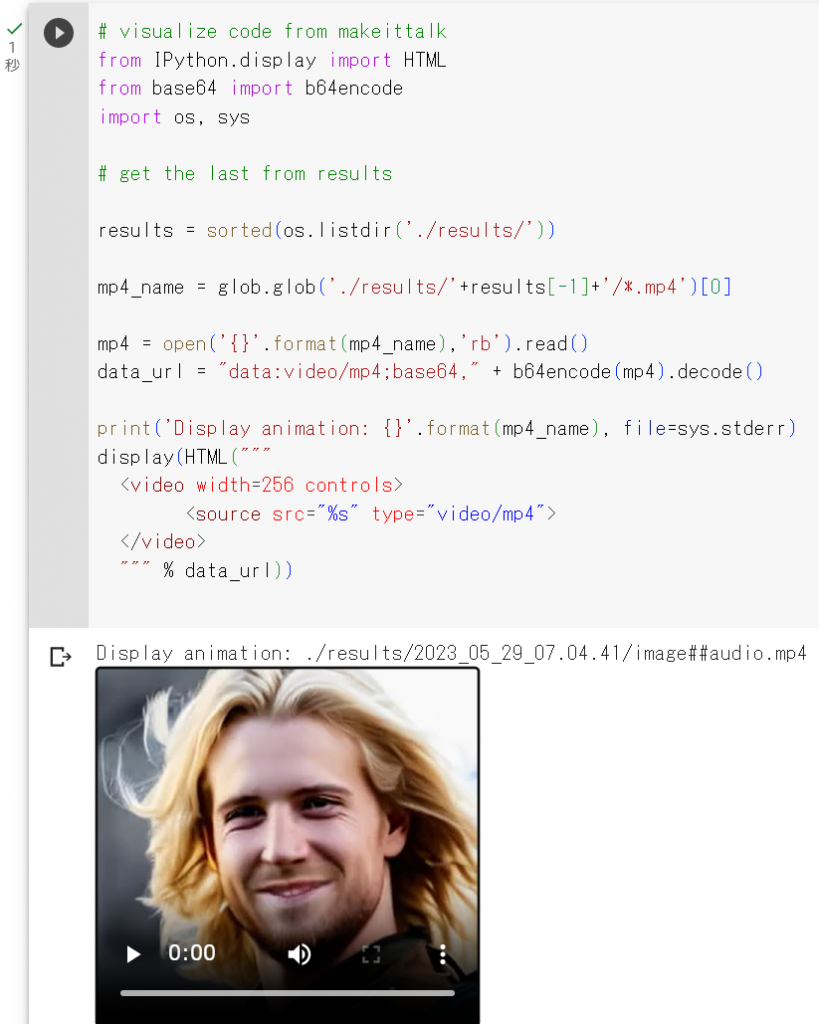
最後まで実行すると、勇者と音声結合され話しているような動画が完成します。
ダウンロード
ダウンロードは、フォルダアイコンをクリックして、resultsフォルダを選択してください。
resultフォルダの中は、日付ごとのファイル名となっております。実行した日付のフォルダを開けば、フォルダ内に完成した動画が格納されています。
一番クオリティが高いのは、image(画像ファイル名)##_audio(音楽ファイル名)_enhanced.mp4になりますので、右クリックでダウンロードすればOKです。
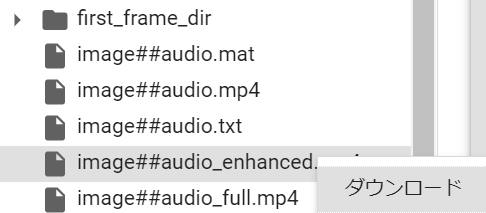
今回作成した動画は次のようになります。
SadTalkerを使えば、画像から人が話す動画が、ウォーターマークのない状態で作成できます。この技術を活用してオリジナルな動画を作成してみましょう!!


コメント